Concurrent CSV exports with Ruby IO pipes
Faster streaming of CSV data

To borrow from Zawinski’s Law: Every web application expands to export CSV data (and you may argue that those applications which cannot so expand are replaced by ones which can).
Basing one’s decisions on data is important and while a business should rely on automated ETL pipelines to feed business intelligence tools, CSV is often used for adhoc, one-off domain reports.
It’s good practice to stream CSV files. It allows you to conserve memory by lazily enumerating over a collection of items you want to generate CSV data for. It also returns data to the client immediately, meaning you don’t have to wait for your data export to start downloading until the full report has been generated.
However, large CSV files may still take a while and if your edge web server is configured to terminate the request after n seconds, the client may have gotten valid, albeit incomplete CSV data. What’s worse: since CSV is a rather liberal text-only format, there isn’t a means to tell whether or not they got the whole or just a partial result.
Reading from a data source (e.g. a database) is IO-bound and while Ruby (or at least MRI) isn’t particularly famous for handling things concurrently, MRI Ruby’s green threads are a perfectly fine way to improve the throughput when faced with IO wait time.
Applied to our CSV export problem, this is what we have to do:
- Split our workload into several chunks
- Add workers to handle the work concurrently and capture their output
- Reconcile intermediary CSV results and stream them to the client
Splitting the work into chunks is almost trivial when working with an
ActiveRecord backend: find_in_batches has everything we
need. For an AR model called MyModel, this is the initial setup:
require "thread"
WORKERS = 3
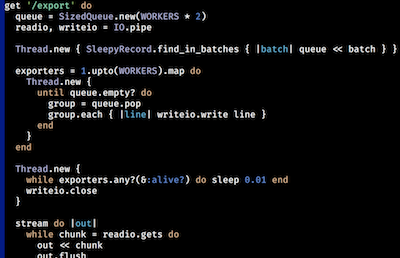
queue = SizedQueue.new(WORKERS * 2)
# Backlog some work! Runs in a separate thread because pushing
# to the queue blocks when the queue is "full"
Thread.new { MyModel.find_in_batches { |batch| queue << batch } }
Capturing your CSV transformer’s output would be easy if the goal wasn’t to
stream every line to the client the moment it becomes available. If you don’t
use streaming, you can still speed up your exports by pushing to a thread safe
collection like Concurrent::Array).
For our purposes, we’ll use an IO pipe as a shared resource between our threads. Simplified, an IO pipe is a pair of endpoints to write data to and read from it again. The read operation blocks until more data is written to the pipe.
readio, writeio = IO.pipe
# This is the worker pool. Create a fixed number of threads
# to get work ie. an ActiveRelation batch) off the queue and
# run the CSV transformation
exporters = 1.upto(WORKERS).map do
Thread.new {
until queue.empty? do
group = queue.pop
group.each { |record| writeio.write MyExporter.call(record) }
end
}
end
Since the workers will start filling the IO pipe immediately, we can add a loop to read from the pipe:
# Create an IO "guard" to close the write buffer when all exporter
# threads have finished, lest we never know when we're done
Thread.new {
while exporters.any?(&:alive?) do sleep 0.01 end
writeio.close
}
while chunk = readio.gets do
# stream this CSV row to the web client
end
You can find a prettier version of these code snippets in this gist on GitHub.
There is one caveat: the CSV rows will be in random order. This is a relatively small price to pay, also considering the fact that reports are likely to be sorted on the client side anyway. However, if you you depend on maintaining the correct order, this approach is not for you.
I created DreamStream (source code on GitHub), a
simple Sinatra app with a mock model called SleepyRecord, to run some
benchmarks: the multi-threaded approach was about 60% faster than the
sequential run. Check out the GitHub repo for more
details.
MRI Ruby’s concurrency model does not have the best reputation and combined with its arguably somewhat clunky syntax to setup threads/processes it has made Ruby developers avoid solving their problems in a concurrent fashion. Knowing when to use Ruby concurrency primitives — dealing with IO — can significantly boost your application’s performance.
comments powered by Disqus